

Have you ever wondered how Netflix recommends movies, or how Siri understands your voice commands?
Allow me to introduce you to machine learning, a groundbreaking field that has the potential to revolutionize industries and our daily lives.
In this post, we’ll explore the fundamentals of machine learning, including its evolution and real-world applications. We’ll shed some light on its challenges and limitations, and guide you on how you can get started with this technology.
Key Takeaways
- Machine Learning is a powerful form of Artificial Intelligence that enables computers to learn from data and identify patterns.
- It has evolved from its inception in the 1940s, with key components including models, algorithms, and data.
- It has practical applications across multiple industries like image/speech recognition, fraud detection & personalization systems.
Understanding Machine Learning
Machine learning is a powerful branch of artificial intelligence. It enables computers to learn from data and make decisions without explicit programming.
Computers can use machine learning algorithms to identify patterns and make predictions, and can efficiently process large data sets at high speed.
At its core, machine learning consists of models, parameters, and learners, which work together to help machines learn from data and improve their performance over time.
The applications of machine learning are vast and diverse, spanning industries such as finance, retail, healthcare, and scientific discovery. It has the potential to transform the way we live and work.
As machine learning techniques continue to advance, we can expect to see even more groundbreaking applications that push the boundaries of human intelligence.
Machine Learning vs. Traditional Programming
Traditional programming relies on human experts to create programs and manually code the logic and rules needed to solve a problem.
In contrast, machine learning automates this process, allowing computers to learn from data without being explicitly programmed with rules.
This offers several advantages, such as the ability to quickly process large data sets, detect patterns and trends in data, and make forecasts based on data.
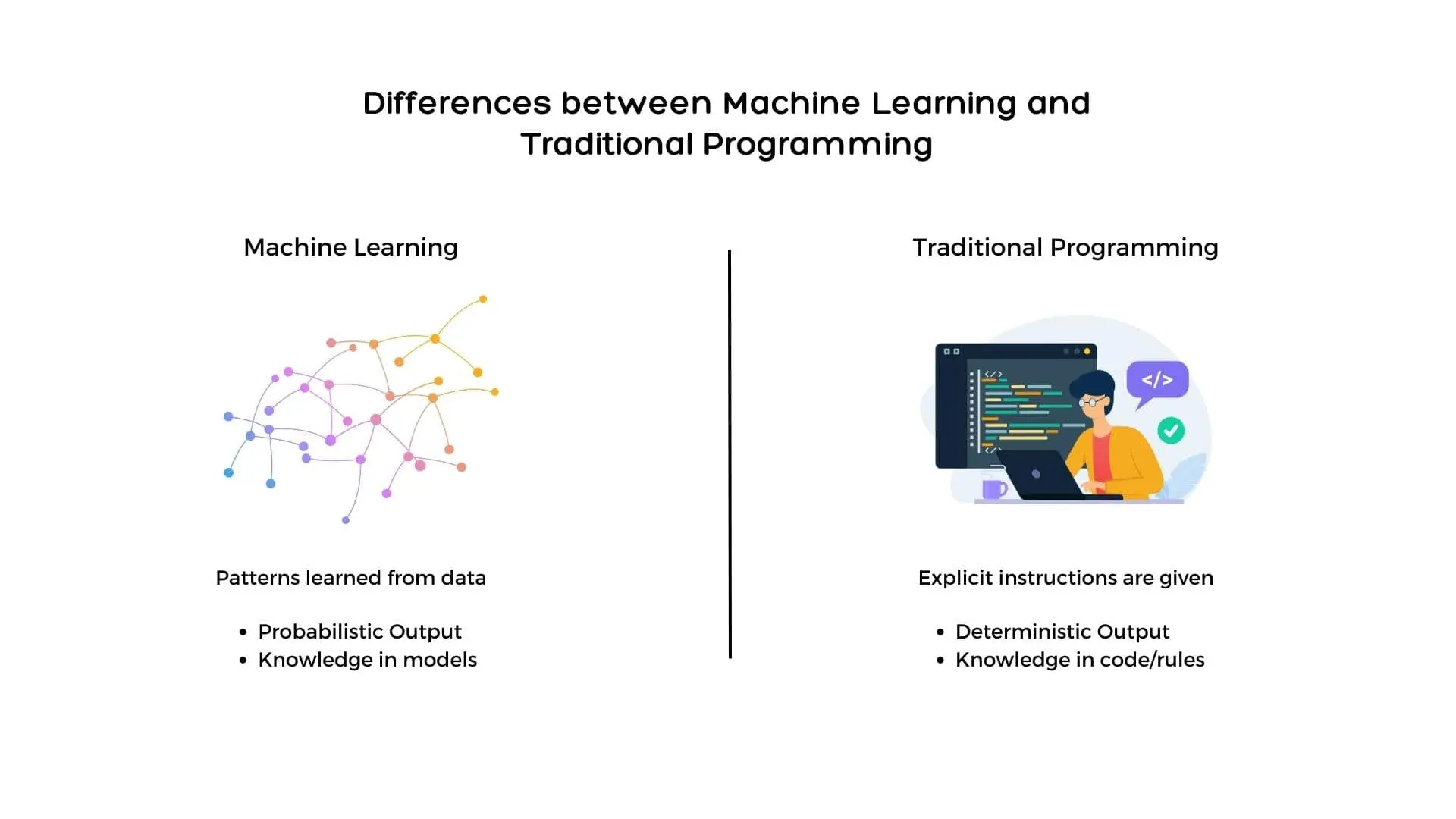
Machine learning also has its drawbacks when compared to traditional programming. It requires substantial data sets for training, can be susceptible to data bias, and debugging machine learning models can be complex.
Despite its challenges, machine learning has found its way into various applications such as:
- Image and speech recognition.
- Personalization and recommendation systems.
- Fraud detection.
While traditional programming continues to excel in tasks like:
- Web development.
- Software development.
- Game development.
Advancements in machine learning have also birthed conversational AI, enabling more interactive and intuitive human-machine dialogues.
Machine Learning and Artificial Intelligence
Machine learning is a key component of artificial intelligence, a broader field that encompasses various strategies and approaches to enable machines to carry out tasks that typically require human intelligence.
While AI deals with both structured and unstructured data, machine learning focuses on structured and semi-structured data, using algorithms and models to learn from data and enhance performance over time.
With the recent advancements in unsupervised machine learning techniques, machines can now learn from unlabeled data, opening up new possibilities for applications in areas where labeled data is scarce.
Machine learning and artificial intelligence are transforming industries and our lives, pushing the boundaries of what machines can do and shaping the future of human-machine collaboration.
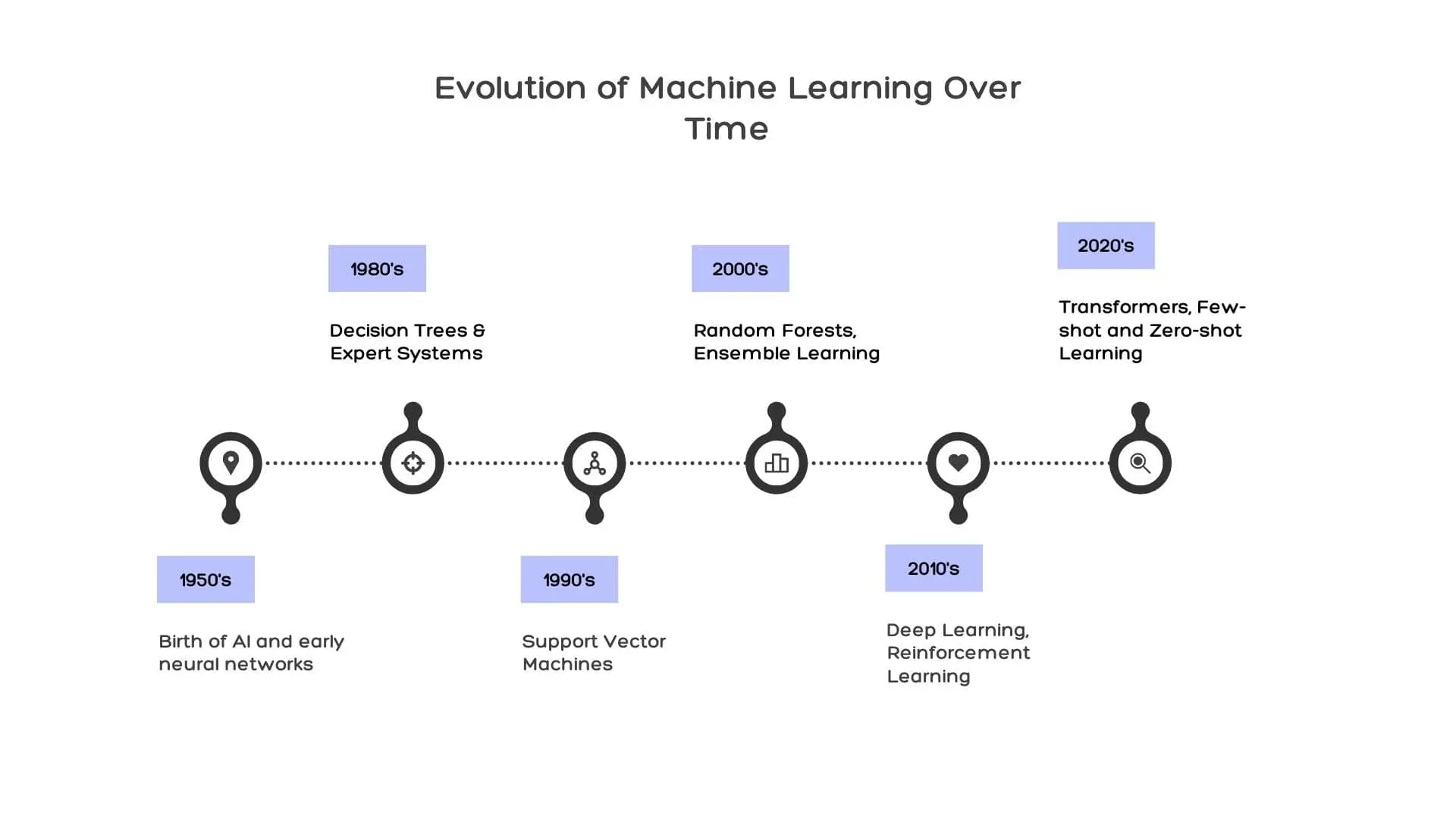
The Evolution of Machine Learning
The journey of machine learning began in the 1940s, with pioneers like Alan Turing, Walter Pitts, Warren McCulloch, and John von Neumann laying the foundation for computation and the development of artificial intelligence.
Since then, machine learning has undergone significant changes, with the 1990s marking a turning point in the field.
Today, machine learning is at the forefront of scientific discovery and technological progress, with the potential to give rise to artificial general intelligence (AGI) – systems capable of learning and executing a wide range of tasks with human-like intelligence.
As machine learning continues to evolve, we can anticipate its impact on various fields of science, technology, and society. Possible future applications include:
- Intelligent assistants.
- Personalized healthcare.
- Self-driving cars.
- Advancements in computer vision.
With each breakthrough and innovation, we come closer to unlocking the full potential of machine learning and its ability to revolutionize the way we live and work.
Pioneers in Machine Learning
The development of machine learning can be attributed to the efforts of visionary pioneers who laid the groundwork for this transformative technology. People like:
- Alan Turing
- Walter Pitts
- Warren McCulloch
- John von Neumann
made significant contributions to the field of computation, shaping the foundations of artificial intelligence. Turing, a British mathematician and logician, was instrumental in pioneering the concept of machine learning in the 1940s.
Other notable figures include Arthur Samuel, who coined the term ‘machine learning’ in 1952 and developed a program for playing championship-level checkers, and Frank Rosenblatt, who created the Perceptron algorithm in 1957, a key element of machine learning.
These trailblazers paved the way for the growth of machine learning, enabling the development of advanced algorithms and models that have revolutionized various industries and our daily lives.
Milestones and Innovations
Throughout its evolution, machine learning has witnessed numerous milestones and innovations that shaped its trajectory. Some of these key moments include:
- The creation of the first mathematical model of neural networks in 1943.
- The Turing Test in 1950.
- The development of the Perceptron algorithm in 1957.
- The introduction of the backpropagation algorithm in 1986.
- The breakthrough of deep learning with convolutional neural networks (CNNs) in 2012.
One of the most emblematic achievements in machine learning history was IBM’s Deep Blue, the first machine to defeat the world champion in the game of chess. Another significant milestone was the victory of AlphaGo, a reinforcement learning algorithm developed by DeepMind, over the world champion in the game of Go in 2016.
These accomplishments serve as a testament to the power and potential of machine learning, as it continues to redefine the boundaries of human intelligence and technological progress.
Key Components of Machine Learning
Machine learning relies on three primary components:
- Models: The structures that generate predictions based on data.
- Algorithms: The methods used to train the models.
- Data: The fuel that drives the learning process.
Together, these components form the foundation of machine learning systems, enabling machines to learn from data and improve their performance over time.
Let’s delve deeper into each of these components and their roles in the machine learning process.
Machine Learning Models
The core of machine learning involves models, parameters, and learners, functioning similarly to the way tools like AI copywriting tools are revolutionizing content creation, demonstrating practical applications of these concepts.
Models serve as the foundation for generating predictions based on data and algorithms.
Machine learning models are trained to map input features to targets based on labeled training data, enabling them to extrapolate from this data and make predictions on new, unseen data.
These models are essential for generating precise predictions and ensuring that machine learning applications are accurate and effective.
Some of the most common machine learning models include:
- Support vector machines.
- Logistic regression.
- Artificial neural networks.
These models are utilized across various machine learning techniques, such as supervised learning, unsupervised learning, and reinforcement learning, to tackle a wide range of problems and challenges in various industries.
As machine learning continues to advance, it’s critical to understand the role and importance of models in generating accurate predictions and driving the success of machine learning applications.
Machine Learning Algorithms
Machine learning algorithms are the methods used to train models, enabling them to learn from data and improve their performance over time.
One machine learning algorithm is tailored to specific types of problems and data.
Some of the most popular machine learning algorithms include:
- Logistic regression.
- Support vector machines.
- Artificial neural networks.
- Clustering algorithms.
These algorithms are employed in various machine learning techniques, such as supervised learning, unsupervised learning, and reinforcement learning, to address different challenges and tasks across diverse industries.
Supervised learning algorithms are used to train models on labeled data, enabling them to make predictions based on input features and target outputs.
On the other hand, unsupervised learning algorithms are used to learn from unlabeled data, allowing machines to recognize patterns and relationships in the data without being explicitly instructed.
The key to choosing the best algorithm for a specific task and guaranteeing the effectiveness of machine learning applications is comprehending the strengths and drawbacks of various machine learning algorithms.
Data in Machine Learning
Input data is the lifeblood of machine learning, as it serves as the fuel that drives the learning process of machine learning models.
Machine learning algorithms depend on data to detect patterns, generate predictions, and enhance their performance over time.
The quality and quantity of data directly impact the accuracy and effectiveness of machine learning models. Without sufficient and high-quality input data, machine learning algorithms would struggle to learn and produce accurate predictions.
Data preparation for model training involves a variety of steps. These steps include:
- Data cleaning and labeling.
- Replacing incorrect or missing data.
- Enhancing and augmenting data.
- Reducing noise.
- Eliminating ambiguity.
- Anonymizing personal data.
- Dividing the data into thoughtful subsets (training, test, and validation sets).
Ensuring the quality and representativeness of data used in machine learning enhances the accuracy and efficacy of models, leading to precise predictions and improved decision-making in diverse applications.
Categories of Machine Learning
Machine learning can be broadly categorized into three main types: supervised learning, unsupervised learning, and reinforcement learning.
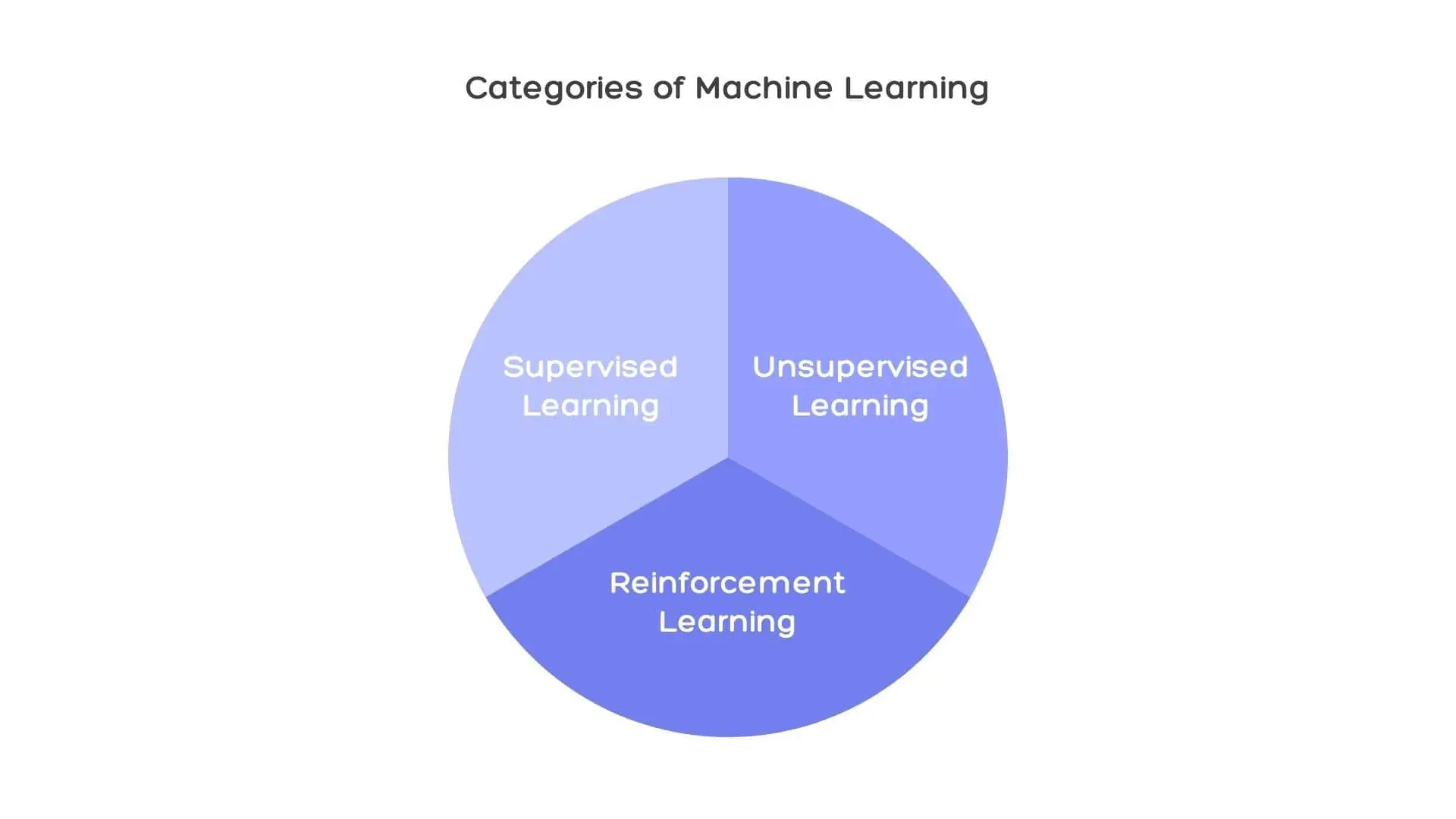
Each of these types has its unique approach to learning from data, with supervised learning using labeled data sets, unsupervised learning using unlabeled data sets, and reinforcement learning using rewards and punishments to facilitate decision-making.
This section will dive into a detailed discussion of each type of machine learning, focusing on their characteristics, advantages, and applications.
Supervised Learning
Supervised machine learning is a type of machine learning in which the algorithm is trained on labeled data sets, allowing it to learn the characteristics of the data set and generate predictions for new data.
This type of learning, also known as supervised learning, is commonly used for tasks such as:
- Image and speech recognition.
- Fraud detection.
- Personalization and recommendation systems.
Some of the most popular supervised learning algorithms include:
- Logistic regression.
- Support vector machines.
- Artificial neural networks.
The primary advantage of supervised learning is its ability to generate highly accurate predictions based on input features and target outputs.
However, this type of learning relies on the availability of labeled training data, which can be time-consuming and expensive to obtain.
Additionally, supervised learning models can be susceptible to overfitting, where the model becomes too specialized to the training data and performs poorly on new, unseen data.
Despite these challenges, supervised learning remains a powerful and widely used approach in machine learning.
Unsupervised Learning
Unsupervised learning is a type of machine learning that focuses on identifying patterns and structures in data without the need for labeled examples.
This type of learning is often used in:
- Natural language processing
- Computer vision.
- Other applications where labeled data is scarce.
Unsupervised learning algorithms, such as clustering algorithms and dimensionality reduction algorithms, are used to uncover hidden patterns and relationships in the data, which can then be applied to new, unlabeled data.
One of the key advantages of unsupervised learning is its ability to learn from unlabeled data, making it a valuable approach when labeled data is not readily available.
However, this type of learning can be more challenging to implement and interpret compared to supervised learning, as the algorithm must learn to recognize patterns and relationships without any guidance from labeled examples.
Despite these challenges, unsupervised learning offers a promising approach to tackling complex problems and uncovering hidden structures in large, unstructured data sets.
Reinforcement Learning
Reinforcement learning is another form of machine learning. Here, an agent learns how to interact with its environment by carrying out various actions and receiving rewards or penalties based on the results.
Reinforcement learning aims to discover the best strategy for taking action in any given situation. This policy is designed to obtain the highest expected return from a sequence of decisions over time.
This type of learning is often used in robotics, game playing, and autonomous vehicles, where an agent must learn to make optimal decisions in a given situation through trial and error.
Reinforcement learning offers several benefits, including:
- The ability to learn from its environment.
- The capability to learn without explicit instructions.
- The potential to learn from delayed rewards.
However, it also faces some challenges, such as the complexity of establishing the environment, the difficulty of tuning the parameters, and the possibility for the agent to become trapped in a local optimum.
Despite these challenges, reinforcement learning continues to drive advances in artificial intelligence and opens up exciting possibilities for the future of machine learning.
Practical Applications of Machine Learning
From self-driving cars to personalized medicine, machine learning has the potential to transform industries and revolutionize the way we live and work.
Let’s review some of the prevalent practical applications of machine learning such as image and speech recognition, fraud detection and risk management, and personalization and recommendation systems.
These applications showcase the power and versatility of machine learning, demonstrating its ability to solve complex problems, uncover hidden patterns, and make accurate predictions across a wide range of domains.
Image and Speech Recognition
Machine learning has made significant strides in the field of image and speech recognition, enabling machines to accurately identify objects, faces, and voices in real-time. Some applications of this technology include:
- Identifying criminals.
- Searching for missing individuals.
- Aiding forensic investigations.
- Intelligent marketing.
- Diagnosing diseases.
- Tracking attendance in schools.
Facial recognition technology is just one example of how machine learning is being used in these applications.
Another notable application of machine learning in this area is Automatic Speech Recognition (ASR), a technology that converts speech into digital text.
ASR has been instrumental in the development of voice assistants like Siri and Google Assistant, as well as transcription services and voice-activated devices.
These advancements in image and speech recognition are a testament to the power of machine learning and its ability to revolutionize the way we interact with technology.
Fraud Detection and Risk Management
Machine learning is increasingly being used in the financial services industry for various purposes, including:
- Detecting and preventing fraud.
- Managing risks associated with lending, investment, and trading activities.
- Analyzing device-specific information, transaction data, and user behavior.
- Identifying fraudulent activities.
- Monitoring financial operations.
- Optimizing trading decisions.
- Carrying out credit scoring.
- Facilitating underwriting.
In addition to fraud detection, machine learning can also be used to examine and verify identity documents for financial fraud prevention, leveraging algorithms to identify inconsistencies in the documents and notify the relevant personnel.
The ability of machine learning to quickly and accurately identify potential fraud and assess risks has made it an invaluable tool in financial services, helping to protect both businesses and consumers from the financial losses associated with fraudulent activities.
Personalization and Recommendation Systems
Machine learning has revolutionized the way we shop, consume content, and interact with online platforms, thanks to its ability to power personalization and recommendation systems.
These systems use historical data to generate personalized recommendations for users, resulting in a more engaging and relevant experience.
E-commerce giants like Amazon and streaming services like Netflix rely heavily on machine learning to provide tailored content based on a user’s past behavior, preferences, and interactions.
In addition to e-commerce and entertainment platforms, machine learning-powered personalization and recommendation systems have also been widely adopted in industries such as social media, online advertising, and even healthcare, where personalized treatment plans can be tailored to individual patients based on their unique genetic makeup and medical history.
The ability of machine learning to deliver highly personalized and relevant experiences is a testament to its potential to transform industries and enhance the way we interact with technology.
Challenges and Limitations of Machine Learning
While machine learning holds tremendous promise and potential, it also faces various challenges and limitations. These challenges include:
- The selection of appropriate algorithms for specific tasks.
- The availability and quality of data for training.
- The interpretation of complex algorithm outcomes.
- The cost of running and tuning machine learning models.
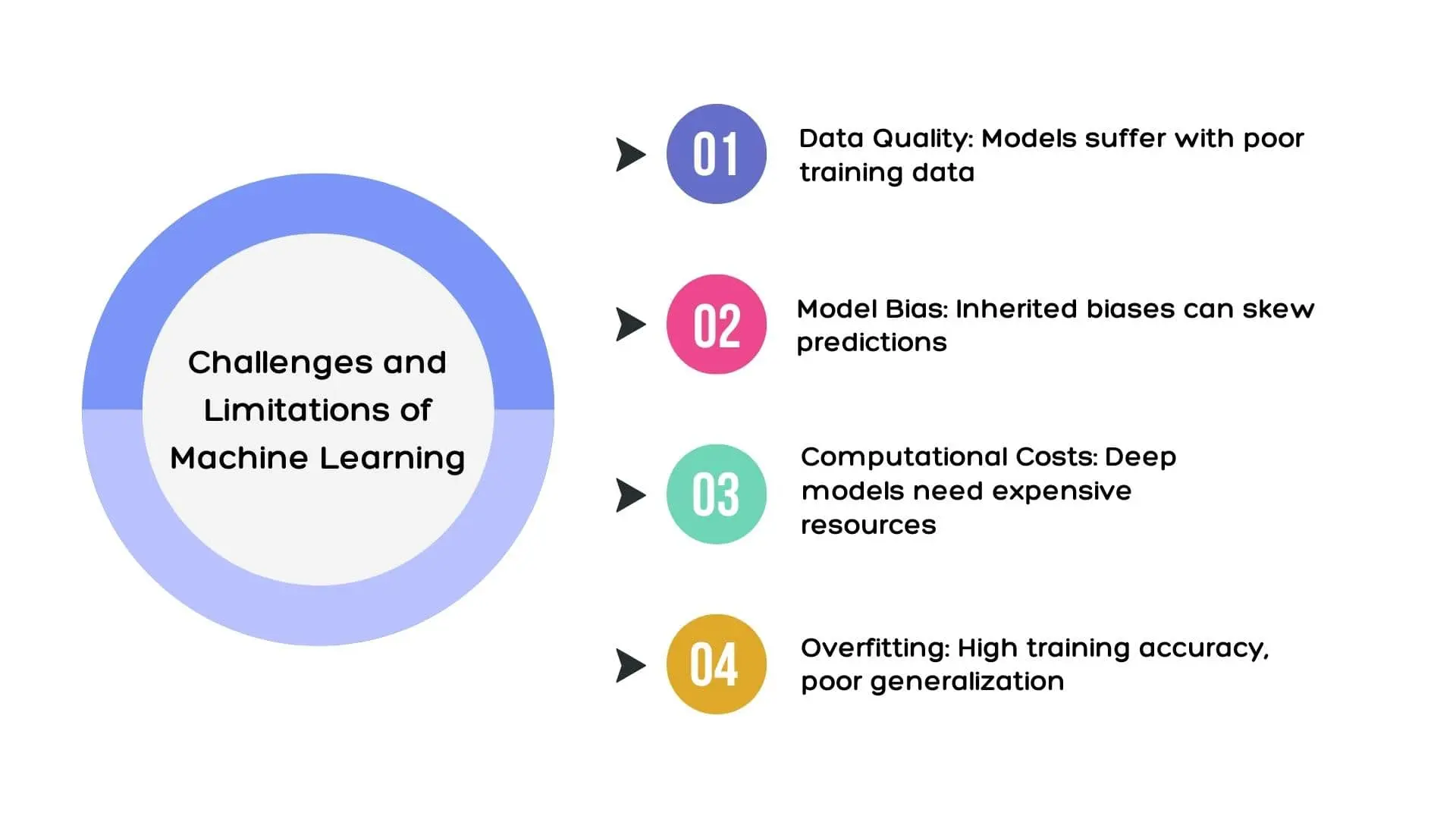
This section will explore further into common challenges and limitations of machine learning, including issues related to data privacy, bias, and computational resources.
Data Privacy and Security
Data privacy and security are of paramount importance in machine learning applications, as they ensure that sensitive information is not accessed or used without authorization, and that individuals have control over their data.
Regulations such as the General Data Protection Regulation (GDPR) in the European Union and the California Consumer Privacy Act (CCPA) in the United States have been introduced to protect the personal data of individuals and grant them greater control over their data.
Machine learning can potentially lead to:
- Indirect access to sensitive information.
- Targeted advertising.
- Biased algorithms.
- Tracking applications.
- Privacy breaches due to mass data collection required for model training.
As machine learning continues to advance and become more widespread, it is crucial to address these data privacy and security concerns to ensure that the benefits of machine learning are realized without compromising the privacy and security of individuals’ data.
Bias and Fairness
Bias and fairness in machine learning refer to the accuracy and fairness of decisions made by machine learning models. Bias arises when a model is trained on data that is not representative of the population, resulting in inaccurate predictions and potentially leading to inequitable outcomes, including discrimination against certain groups of people.
Fairness, on the other hand, is the notion that decisions made by a machine learning model should be equitable and not discriminate against certain groups of people.
To ensure that machine learning models are both accurate and fair, it is essential to carefully select and preprocess the data used for training, as well as to evaluate the performance of the model on diverse and representative data sets.
By addressing issues of bias and fairness in machine learning, we can work towards creating:
- More accurate algorithmic decision-making processes.
- More equitable algorithmic decision-making processes.
- More transparent algorithmic decision-making processes.
These improvements will benefit everyone.
Computational Resources
Machine learning relies heavily on computational resources to process large amounts of data, train models, and generate predictions.
This can result in high computational demands, scalability challenges, time-consuming training processes, and significant energy consumption.
Resource constraints can also hinder the use of data for training, limit the sophistication of models, and reduce the rate of model training.
As machine learning continues to evolve and push the boundaries of what machines can do, it is essential to address these challenges and develop more efficient and scalable algorithms and models. Doing so will enable us to:
- Harness the full potential of machine learning.
- Minimize its impact on the environment.
- Ensure that its benefits are accessible to a wide range of users and industries.
Getting Started with Machine Learning
If you are interested in diving into the world of machine learning, there are numerous resources available to help you get started. Some of these resources include:
- Online courses and tutorials.
- Books on machine learning.
- Forums and online communities.
- Coding platforms and libraries.
- Data sets for practice.
With these resources, you can learn the fundamentals of machine learning and begin applying it to real-world problems.
This section will offer guidance on initiating the learning journey and working with machine learning, which includes recommendations on programming languages, tools and libraries, and additional learning resources.
Python for Machine Learning
Python is a popular programming language for machine learning, thanks to its user-friendly syntax, extensive library ecosystem, and strong community support.
Its simplicity and readability make it an ideal choice for beginners, while its versatility and power make it suitable for advanced users and researchers alike.
By choosing Python as your primary programming language for machine learning, you can take advantage of the wealth of resources and tools available to help you learn and apply machine learning techniques.
In addition to Python, there are other programming languages and tools that can be used for machine learning, such as R, Julia, and MATLAB. However, Python remains the most popular choice due to its ease of use, versatility, and extensive library ecosystem, making it an excellent starting point for anyone looking to get started with machine learning.
Essential Tools and Libraries
To successfully work with machine learning, you’ll need to familiarize yourself with a variety of tools and libraries that can help you with tasks such as data manipulation, visualization, and algorithm implementation. Some of the most essential tools and libraries for machine learning include:
- NumPy for numerical computing.
- Matplotlib for data visualization.
- Pandas for data manipulation.
- Scikit-Learn for machine learning algorithms.
- TensorFlow for deep learning.
- PyTorch for deep learning.
- Keras for deep learning.
These tools and libraries each serve a specific purpose and offer unique advantages, making them indispensable for anyone working with machine learning.
By mastering these tools and libraries, you’ll be well-equipped to tackle a wide range of machine learning problems and challenges, including:
- Data preprocessing.
- Feature engineering.
- Model training.
- Model evaluation.
Learning Resources
There are numerous learning resources available to help you get started with machine learning, catering to different learning styles and preferences.
Some of the most popular resources include online courses, such as Coursera’s Machine Learning course and Google’s Machine Learning Crash Course, which provide comprehensive and interactive learning experiences for beginners and experienced learners alike.
In addition to online courses, you can also find a wealth of information in:
- books
- tutorials
- videos
- online forums
- open source projects
These resources provide opportunities to collaborate with other learners and practitioners in the machine learning community.
By exploring these resources and engaging with the community, you can deepen your understanding of the field, develop new skills and competencies, and stay up-to-date with the latest trends and developments in machine learning.
Wrapping Up
In this post, we’ve explored the world of machine learning, diving into its fundamentals, evolution, and practical applications across various industries. We’ve also discussed the challenges and limitations of machine learning, as well as the importance of data privacy, bias, and computational resources.
Finally, we’ve provided guidance on getting started with machine learning, including recommendations for programming languages, tools, and libraries, as well as learning resources.
The expansive nature of machine learning presents numerous opportunities, not just in technological advancement but also in entrepreneurial ventures. Those interested in the intersection of AI and business might find exploring how to make money with AI particularly intriguing.
With this knowledge in hand, you are ready to embark on your machine learning journey and unlock the potential of this transformative technology to change the world.
